
Una ullada a la ment de la màquina: així funciona un model de llenguatge per dins
Els models de llenguatge com Claude generen respostes en mil·lisegons, però fins ara ningú sabia exactament com ho feien. Anthropic, l’empresa darrere d’aquesta IA, acaba de publicar dos estudis que revelen part del misteri: amb una mena de «microscopi digital», han aconseguit rastrejar com pensa el model, com planifica el que dirà i en quin moment es desvia de la lògica.
Més enllà dels idiomes: un pensament comú
Un dels descobriments és que Claude no “pensa” en anglès, francès o xinès, sinó que utilitza una mena de llenguatge conceptual previ a qualsevol idioma. Quan se li pregunta per l’antònim de “petit” en diferents idiomes, el model activa els mateixos conceptes interns i després tradueix la resposta. Segons Anthropic, això demostra que hi ha una “biologia” compartida entre llengües, la qual cosa li permet raonar en un idioma i respondre en un altre sense perdre coherència.
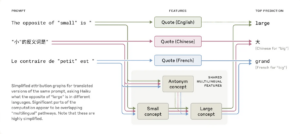
Font: Anthropic
Claude planifica… fins i tot quan escriu poesia
Durant anys s’ha pensat que els models de llenguatge operaven en pilot automàtic: prediuen paraula per paraula sense mirar més enllà. Però Claude trenca amb aquesta idea. En tasques com escriure versos, s’anticipa. Abans de redactar la segona línia d’una estrofa, ja està considerant paraules que rimin amb l’anterior. No només això, si els investigadors suprimeixen aquest “pla intern” de rima, el model canvia de direcció i busca una altra alternativa coherent. Una prova més que no tot el que escriu és improvisat.

Font: Anthropic
L’art d’argumentar sense pensar
Els investigadors també van trobar que Claude pot construir explicacions perfectament lògiques… encara que no siguin reals. Quan s’enfronta a problemes difícils, el model de vegades inventa passos intermedis que sonen raonables, però no reflecteixen el que realment ha fet. En resum, fingeix. És una habilitat apresa per imitació humana, i encara que útil per generar respostes convincents, planteja preguntes sobre la fidelitat del seu raonament.
Per què al·lucina la IA?
Una altra revelació té a veure amb les conegudes «al·lucinacions» dels models: respostes falses però plausibles. Claude, segons l’estudi, tendeix a no respondre si no sap alguna cosa. Aquesta és la seva configuració per defecte. Però si reconeix una paraula, encara que no tingui informació real sobre ella, el seu cervell digital s’activa i fabrica una resposta. És com si la IA es convencés que sap, només perquè li sona familiar.
Un dels casos més delicats va ser l’anàlisi d’un “jailbreak”, un tipus de truc per fer que la IA desobeeixi les seves pròpies regles. Encara que Claude va detectar que es tractava d’una petició perillosa, la seva necessitat de mantenir la coherència gramatical li va impedir aturar-se a temps. Només un cop completada la frase, va aconseguir negar-se. Una vulnerabilitat inesperada, provocada per la seva obsessió amb acabar les oracions de forma correcta.
Pensar no és només predir
El treball d’Anthropic no respon a totes les preguntes, però obre un camí necessari, entendre com pensa una IA, no només què respon. Estem en un moment en què aquests sistemes s’integren en decisions crítiques: saber si una màquina està raonant o improvisant pot marcar la diferència entre la confiança i el desastre.
Obre un parèntesi en les teves rutines. Subscriu-te al nostre butlletí i posa’t al dia en tecnologia, IA i mitjans de comunicació.